This app brings OCR functionality to Dynamics 365 entity forms.
The user can drag and drop an image or PDF file into the entity form, and the module will extract the information from the file to generate the corresponding entity record.
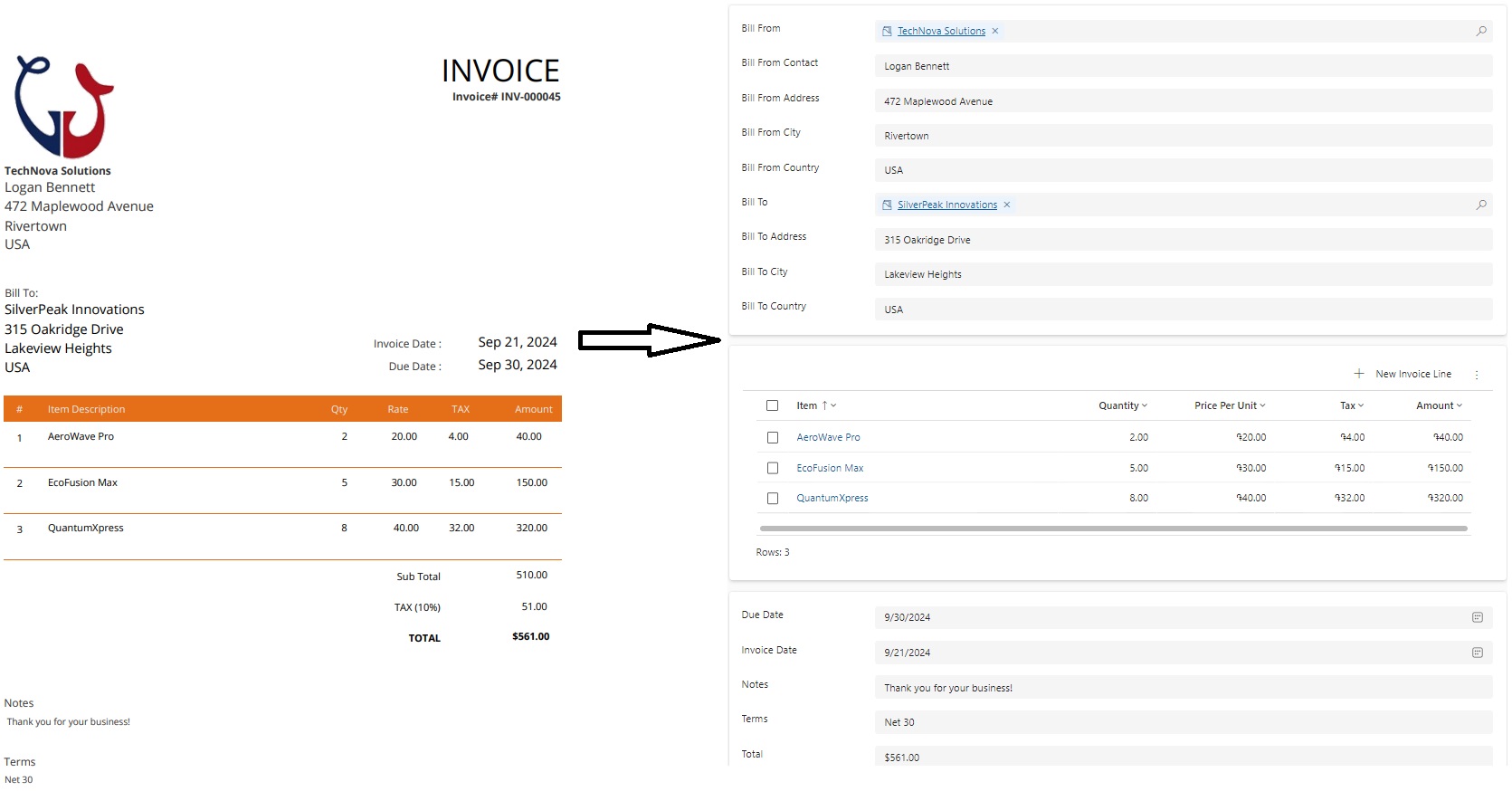
To operate correctly, administrators must first configure the following two components in Azure.
- Document Intelligence
- Storage Account
Watch the video for step-by-step instructions on setting up Azure components and connecting them to the Document OCR module.
Then, administrators need to set up an OCR model and associate with the entity. Each document or image layout requires a separate model. The model is used to map the fields between the document/image layout and the entity fields. An entity can be associated with multiple models, where each model is trained on a specific layout of an image or PDF file.
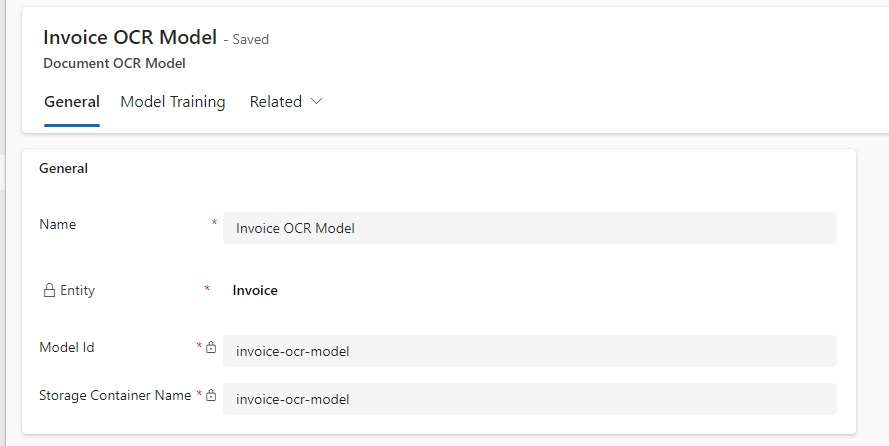
| Field | Description |
|---|---|
| Name | The name of the model |
| Entity | The entity linked to the model |
| Model Id | The unique ID of the model is stored in Azure |
| Storage Container Name | The unique name of the storage container connected to the model |
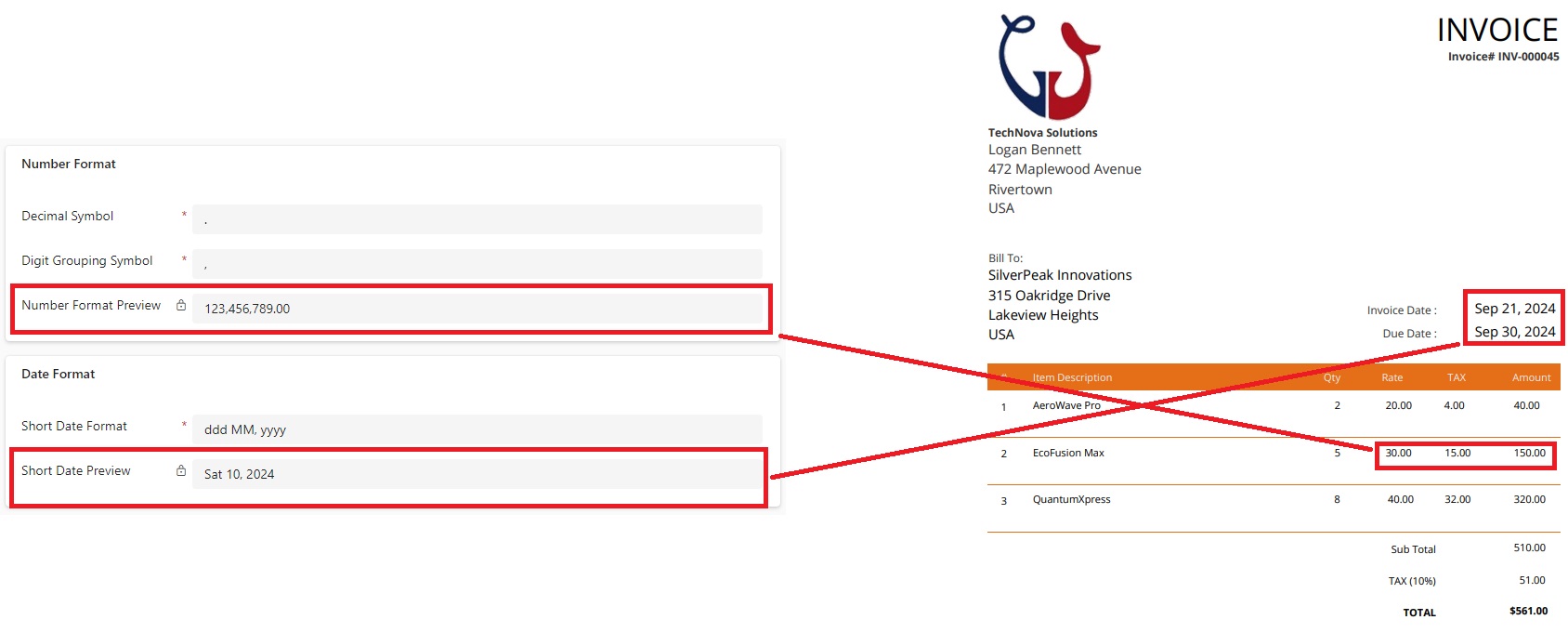
In the model entity, administrators should also configure the number and date formats to match those in the PDF or image layout.
Then, under the "Training" tab upload at least 5 examples of .pdf or image files with the same layout to train the model. After, you need to annotate the document, which involves linking specific text from the document to the corresponding entity fields in Dynamics 365.
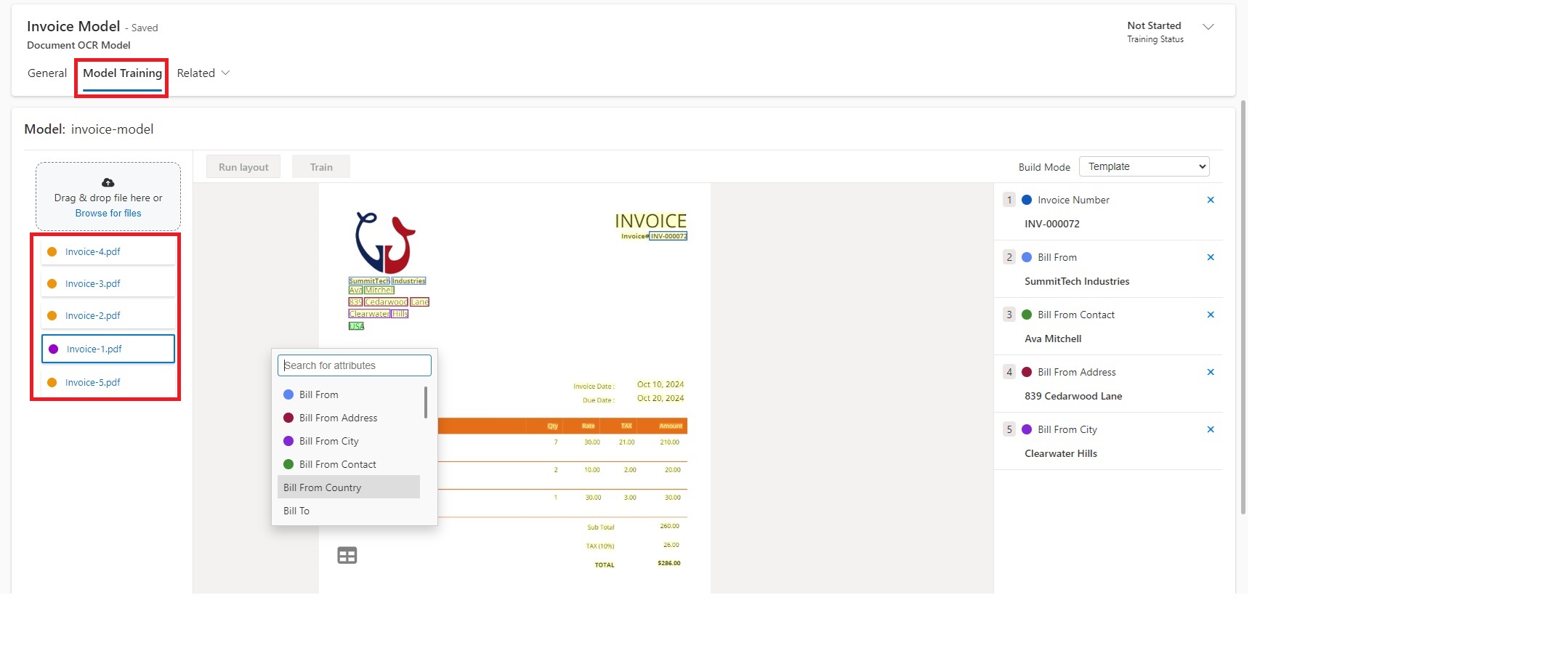
Watch the video for step-by-step instructions on how to annotate the documents.
Administrators should then include a drag-and-drop control within the entity form. To do this, the "BeverControls.DocumentOCR.DragAndDropArea" control should be applied to any "Single Line of Text" field.
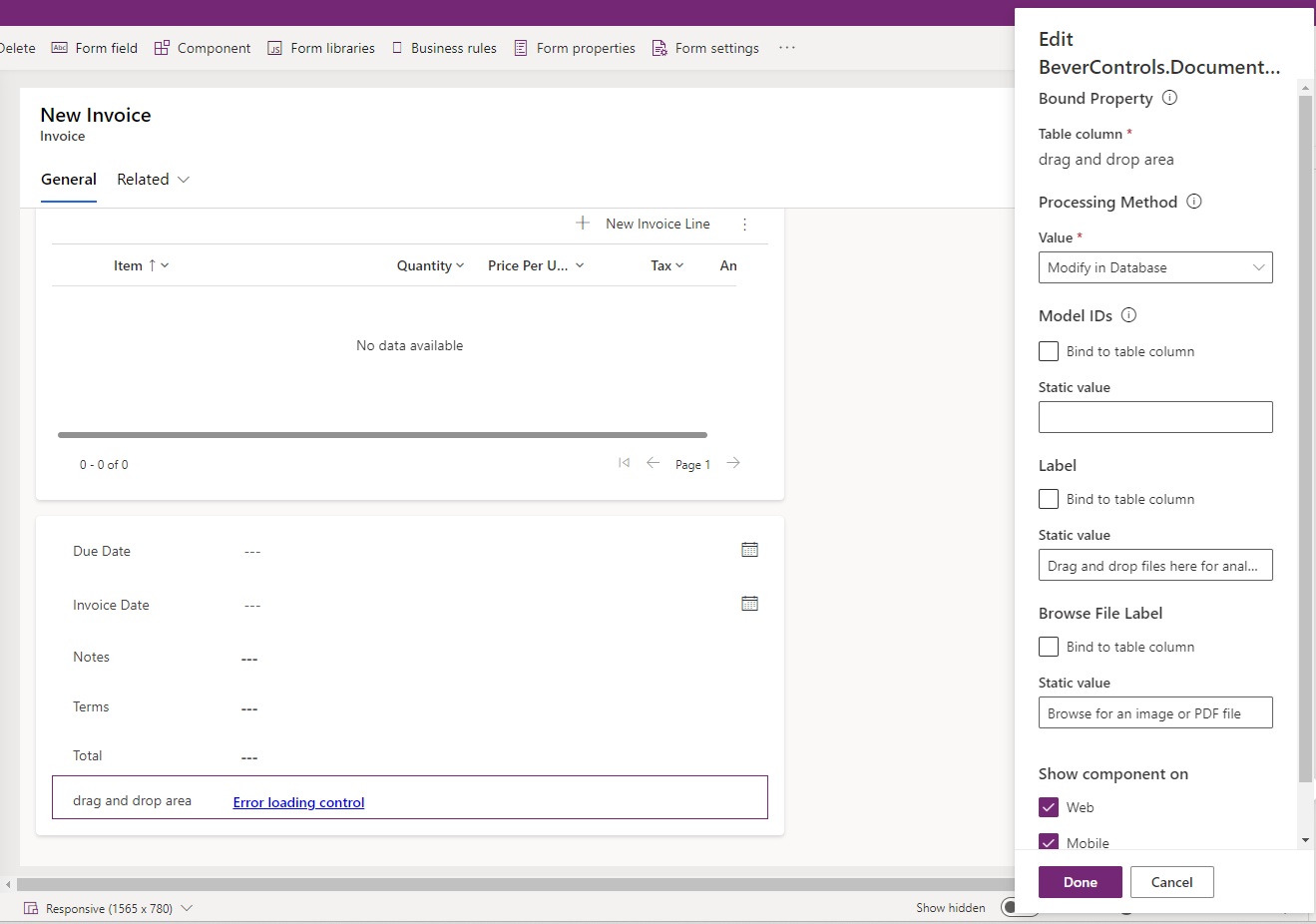
The control has the following properties.
| Property | Description |
|---|---|
| Processing Method | This setting is used to either automatically populate the form with extracted values or to modifly a record in the database Modify in Database – After drag and drop, the system will return the extracted data to fill in the form and will create a new record (or update an existing record) Autofill Form – After drag and drop, the system will return the extracted data to fill in the form but will not create or update any records in the system |
| Model IDs | Comma-separated model IDs. If not specified then the default value is all model IDs where the model entity is the current entity. Used to instruct control on which models run the uploaded file. A model with the highest confidence percentage will be selected |
| Label | Used to define the label displayed in the drag-and-drop area |
| Browse File Label | Used to define the browse file label displayed in the drag-and-drop area |
The Document OCR module provides developers with the following actions/APIs.
This API retrieves all OCR models related to a specified entity. It takes the entity schema name as input and returns all related model entity records in JSON format.
- URL: /api/data/v9.2/bvr_document_ocr_retrieve_models
- Method: POST
-
Request Body:
- Entity: The schema name of the entity
-
Response:
- OutputData: Related model entity records in JSON format

This API takes the model ID and a base64-encoded document string as input parameters and returns a confidence percentage. This confidence percentage indicates the system’s level of certainty that the provided document can be accurately processed by the given OCR model.
-
URL: /api/data/v9.2/bvr_document_ocr_analyze_document
-
Method: POST
-
Request Body:
- Model: The ID of the OCR model that will be used to analyze the document
- ReturnOnlyConfidenceRate: When set to true, the API will only return the confidence percentage. When set to false, it will provide both the confidence percentage and the extracted text from the document
- Document: The document in base64 format that is to be analyzed
-
Response:
- OutputData: The confidence percentage along with all the extracted text from the document, provided in JSON format

This API extracts data from the document using the specified model. It returns the extracted text, mapped to the entity fields defined during the model training.
- URL: /api/data/v9.2/bvr_document_ocr_extract_document_data
- Method: POST
-
Request Body:
- Model: The ID of the OCR model that will be used to extract data from the document
- Entity: The schema name of the entity connected to the model
- ModifyInDatabase: When set to true, the API will return the extracted data and either create a new record or update an existing one in Dynamics 365 if the record ID is provided. If set to false, the system will only return the extracted data without creating or updating any records.
- RecordId (Optional): If the ModifyInDatabase parameter is set to true and the user intends to update an existing record, the record ID can be specified in this parameter. Otherwise, this parameter will be ignored
- Document: The document in base64 format from which the data is to be extracted
-
Response:
- OutputData: The data extracted from the document, provided in JSON format
